Short Paper A Low-Volatility Strategy based on Hedging a Quanto Perpetual Swap on BitMEX
Daniel Atzberger, Toshiko Matsui, Robert Henker, Willy Scheibel, Jürgen Döllner, and William Knottenbelt
2nd IEEE International Workshop on Cryptocurrency Exchanges (CryptoEx 2024)
BibTeX , Abstract
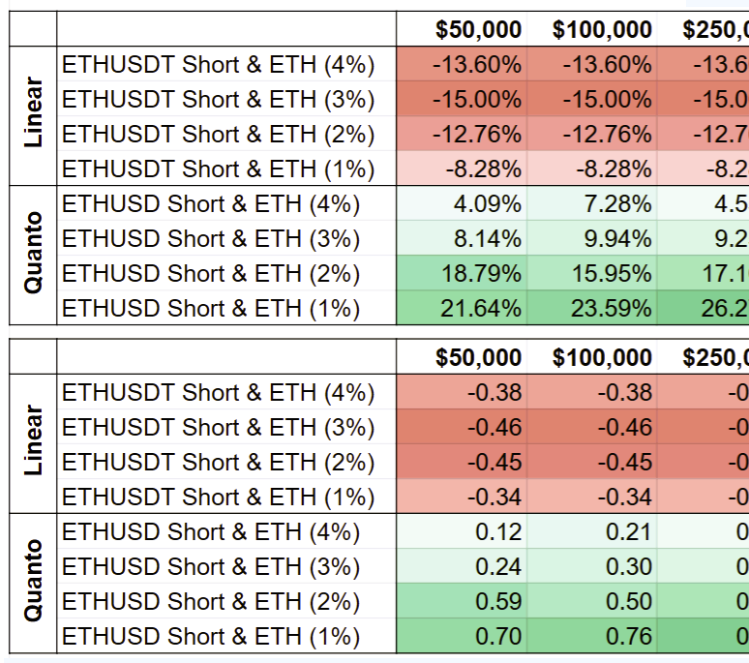
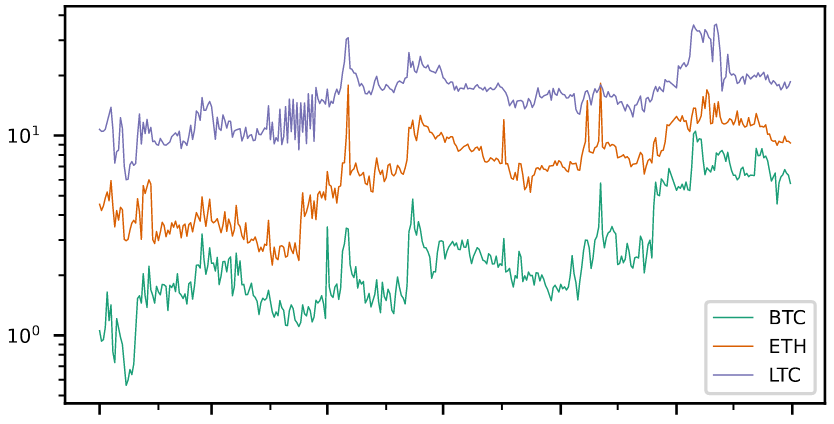
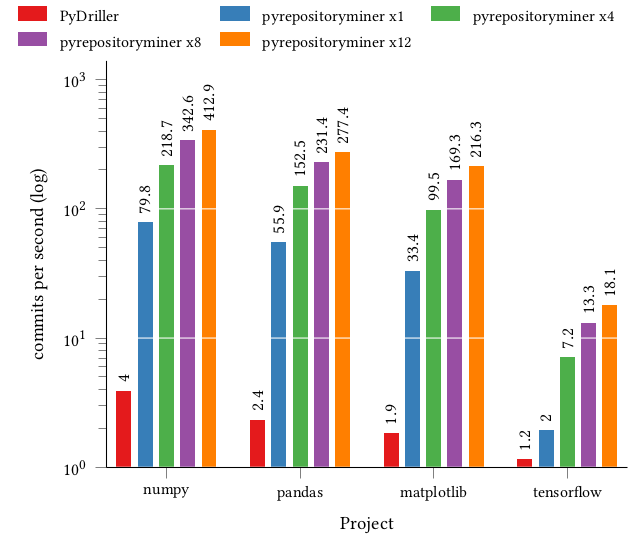
In 2016, BitMEX introduced a novel type of crypto derivates: Perpetual Swaps, i.e., futures with an infinite term. Perpetual swaps provide a new strategic risk management tool for cryptocurrencies due to their custody-free nature, high leverage, and funding mechanism, but there has been little quantitative analysis on the their benefits. In this paper, we introduce a trading strategy that combines a Quanto Perpetual Swap with a spot position to benefit from the funding mechanism. We compare our strategy with a long-only investment in the underlying cryptocurrency and a similar strategy based on Linear Perpetual Swaps to evaluate their performances in a large-scale backtest covering the years 2021 and 2022. Our analysis shows that our strategy generates positive returns in bullish market phases of the underlying with lower volatility.
In press
Publisher Record, Author Version
@InProceedings{atzberger2024-perpetual-swaps,
author = {Atzberger, Daniel and Matsui, Toshiko and Henker, Robert and Scheibel, Willy and D{\"o}llner, J{\"u}rgen and Knottenbelt, William},
title = { A Low-Volatility Strategy based on Hedging a Quanto Perpetual Swap on BitMEX },
year = {2024},
series = {CryptoEx '24},
publisher = {IEEE},
booktitle = {Proceedings of the 2nd International Workshop on Cryptocurrency Exchanges},
note = {in press},
}